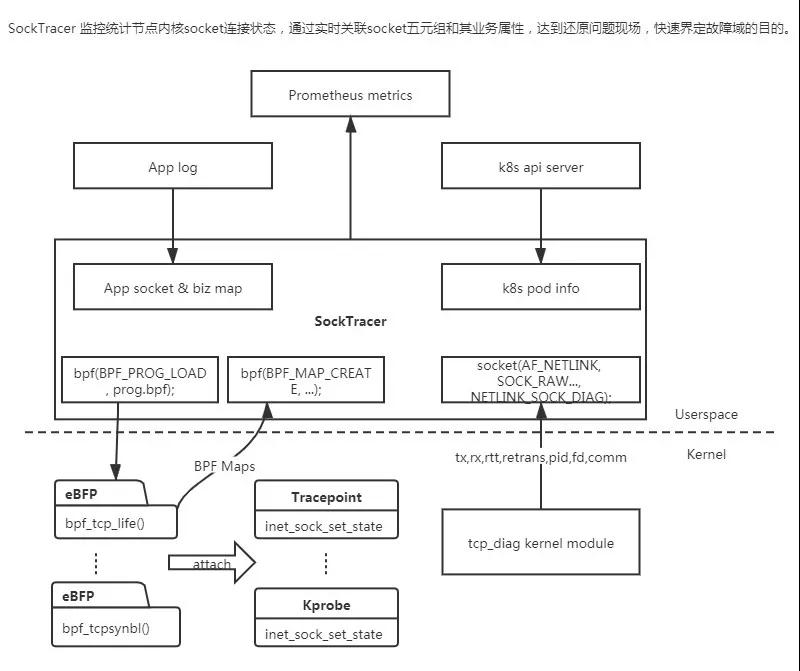
开篇综述:Socket Tracer定位是传输层(Socket&TCP)的指标采集工具,通过补齐网络监控的这部分盲区,来达到快速界定网络问题的目标。
一、背景
随着软件应用的集群化、容器化、微服务化,产品的稳定性越来越依赖网络。现有的专有云和一体机产品,部署在裸机,从硬件服务器、交换机到os都是不可靠的,且监控盲区较多,其中网络是重灾区。对于网络不稳定导致的中间件链接超时、设备掉线、视频推流卡顿等问题,缺乏有效的网络层监控指标定界问题。一旦现场不存在,由网络引发的问题很难定位。现有的网络监控方案,都集中在网卡维度做流量、错包等指标统计,粒度过粗,只有从Socket和TCP连接维度,监控socket缓存状态,采集TCP建连、断开、实时流量、延迟、重传等信息,才可以最直接的反映业务的网络状态。
二、目标
现有的网络监控工具如 ss、netstat 等,可以显示服务器当前 Socket 状态快照,在问题现场可以有效的辅助我们排查问题。当现场不存在,我们希望能有工具能保存历史网络状态。然而单纯记录历史 Socket 五元组信息,在复杂拓扑场景是不够的,因为IP很可能是动态的,还须将当前时刻的 Socket 连接和业务属性(Pod Name、设备身份...)关联,才能达到还原问题现场,快速界定故障域的目的。
1.典型场景
- 集群中间件访问超时问题定界。
- 数据采集丢包问题定界:例如设备侧声称发包,但网关没有收到,现场不在了,互相扯皮。
- 设备连云链路检测。
- 视频直播卡顿问题定界。
- ...
2.能力综述
Socket维度信息采集
- 流量(tx/rx)、延迟(srtt),待重传包数量、总重传次数、收发队列长度,Accept队列长度。
- TCP 生命周期监控:监听TCP Close事件,统计连接时长,收发包总字节数。
- TCP Reset异常监控:收到或者发送Reset的异常,及异常时刻的TCP State。
云原生监控方案适配
- 现有的netstat、ss等网络信息统计工具,无法做到跨network namespce的socket信息统计。在云原生环境使用不便。需要做到监控k8s集群所有节点,及节点上所有Pod的Socket状态。
- 采集数据指标化,支持对接 Prometheus 的 Exporter 接口。
- 支持指标推送到 VictoriaMetrics。
指标选取原理
TCP的指标有很多,为什么采集上述的指标信息,出发点是希望找到可以反映应用程序状态和网络连通状态指标,如果有其它指标采集建议也欢迎留言。下面展开分析下上述指标的采集原因:
1)TCP Retransmit
包重传的超时时间是RTO,通常是200ms左右,当我们观察到一段时间出现了TCP包重传,后续又恢复正常了,可以判断这个时间段出现了网络抖动, 就可以找网络的同学来帮忙排查问题了。
2)TCP SRTT
RTT(round-trip time)为数据完全发送完(完成最后一个比特推送到数据链路上)到收到确认信号的时间。
SRTT(smoothed round trip time)是平滑过的RTT。
通过srtt历史曲线图或柱状图,观察出来延迟的区间变化,就可以知道网络连接的srtt是否抖动。如果业务延迟发生了抖动,srtt很稳定,就可以说明大概率不是网络的问题,可能是业务的问题,或者调度的问题等等; 反之,如果srtt也发生了抖动,那么可以先检查一下网络连接。
3)TCP Tx/Rx
监控链接的流量,结合对现场业务的理解,在业务出现丢失数据场景,可以辅助定位时网络问题还是应用问题:
- 传输层收到数据,但堆积在rcv_queue中,可能是应用层处理代码阻塞。
- 传输层Rx没有增加,则很可能是对端没有发送数据。
4)TCP reset reasons
Reset 包是导致TCP异常断开的常见原因之一,下面对可能触发 reset 事件的原因做一个汇总(如有错漏欢迎补充):
- Non-Existence TCP endpoint: Port or IP(Restrict Local IP address):服务端不存在。(SYN -> Server reset)
- TCP SYN matches existing sessions:服务端、或者防火墙已存在相同5元组连接。(SYN -> Server reset)
- Listening endPoint Queue Full :应用层没有及时accept,导致服务端Accept队列满(全链接队列满),分两种情况:对于新来握手请求 SYN -> SYN包会被Server默默丢弃,不会触发reset;碰巧在Client 回 ACK(握手第三个包)时,accept 队列满了,Server 会根据 tcp_abort_on_overflow sysctl 配置,决定是否发送 reset。
- Half-Open Connections:服务端程序重启,导致链接信息丢失。(中间数据-> Server reset)
- RESET by Firewalls in transit:在防火墙维护session状态的场景(NAT网关),防火墙Session TTL过期。(中间数据-> FW reset)
- Time-Wait Assassination:Client Time-Wait 期间,收到 Server 端迟到的数据包,回送Ack给Server,导致Server发送Rst包。(Server 迟到数据 -> Client Ack-> Server Reset)
- Aborting Connection:客户端Abort,内核发送reset给服务端。(Client Reset)
三、实现原理
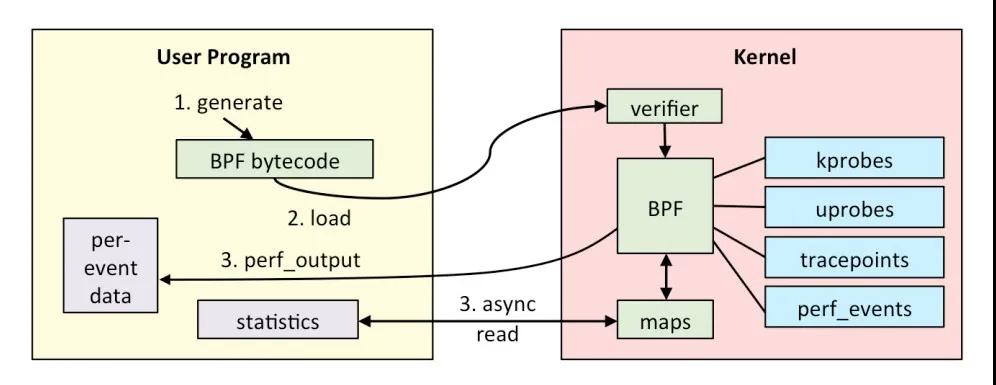
Socket Tracer 使用 eBPF+Tracepoint 捕捉 TCP 的 reset&new&close 等事件,使用 netlink + tcp_diag 周期抓取内核 Socket 信息快照。
1.eBPF
背后的思想是:“与其把数据包复制到用户空间执行用户态程序过滤,不如把过滤程序灌进内核去”。
eBPF 是一个在内核中运行的虚拟机,它可以去运行用户。在用户态实现的这种 eBPF 的代码,在内核以本地代码的形式和速度去执行,它可以跟内核的 Trace 系统相结合,给我们提供了几乎无限的可观测性。
eBPF 的基本原理:它所有的接口都是通过 BPF 系统调用来跟内核进行交互,eBPF 程序通过 LVM 和 Cline 进行编译,产生 eBPF 的字节码,通过 BPF 系统调用,加载到内核,验证代码的安全性,从而通过 JIT 实时的转化成 Native 的 X86 的指令。eBPF整体架构如下:
2.kprobe
当安装一个kprobes探测点时,kprobe首先备份被探测的指令,然后使用断点指令(即在i386和x86_64的int3指令)来取代被探测指令的头一个或几个字节。
当CPU执行到探测点时,将因运行断点指令而执行trap操作,那将导致保存CPU的寄存器,调用相应的trap处理函数,而trap处理函数将调用相应的notifier_call_chain(内核中一种异步工作机制)中注册的所有notifier函数,kprobe正是通过向trap对应的notifier_call_chain注册关联到探测点的处理函数来实现探测处理的。
当kprobe注册的notifier被执行时,它首先执行关联到探测点的pre_handler函数,并把相应的kprobe struct和保存的寄存器作为该函数的参数,接着,kprobe单步执行被探测指令的备份,最后,kprobe执行post_handler。等所有这些运行完毕后,紧跟在被探测指令后的指令流将被正常执行。
3.tracepoint
tracepoint和kprobe相比,tracepoint是一个静态的hook函数,是预先在内核里面编写好才使用。tracepoint实现是基于hooks的思想,在函数的入口就被放置一个probe点,这个probe点就会跟踪调用这个函数的各种信息,并将追踪的信息保存到一个环形队列中去,如果用户希望读取这些内核,就会通过debugfs形式来访问。
4.方案选型
eBPF 调用方案
对比调用eBPF能力的三种方案,bpftrace / bcc / libbpf,最终选择bcc:
- bpftrace提供了脚本语言,方便输出内核信息到控制台,做CLI工具很方便。但没有提供API接口,不方便后台代码调用和信息读取。
- libbpf会直接把内核bpf代码编译成bin文件,再放到目标机运行。目标是一次编译,四处运行,为了解决跨内核版本(配置)的可移植问题,需依赖BTF kernel选项,目前绝大部分内核默认没有打开该功能,需要修改配置重新编译kernel才行。
- bcc在目标机环境运行阶段,动态编译bpf内核代码,来解决可移植性问题。是现阶段使用最广的方案,绝大部分bpf监控工具都基于bcc-tools;并且提供API接口,便于代码集成,其中内核代码基于C语言,应用层代码提供python和go两种语言API。
Socket 信息采集方案
eBPF+kprobe在目标函数上动态挂载hook函数,在高频调用(收发包函数)的场景额外开销较大,因此在周期统计socket链接收发数据量、重传次数等场景,我们参考 ss 的实现,基于 linux netlink + tcp_diag 内核模块,该方案适合应用主动抓取某个时间点socket 统计信息快照,可以减少额外性能开销。
5.整体架构图
四、部署和配置方法
1.命令行参数定义
包含Socket采集过滤配置文件路径,socket信息采集周期,vm-insert的URL地址。
2.Socket采集过滤配置文件格式
一台服务器上的Socket连接数量非常多,数据量和比较大,我们往往只关心部分服务的相关连接,就像tcpdump我们也往往会对IP和端口做过滤一样。过滤配置文件使用yaml格式,定义如下:
五、前台展示
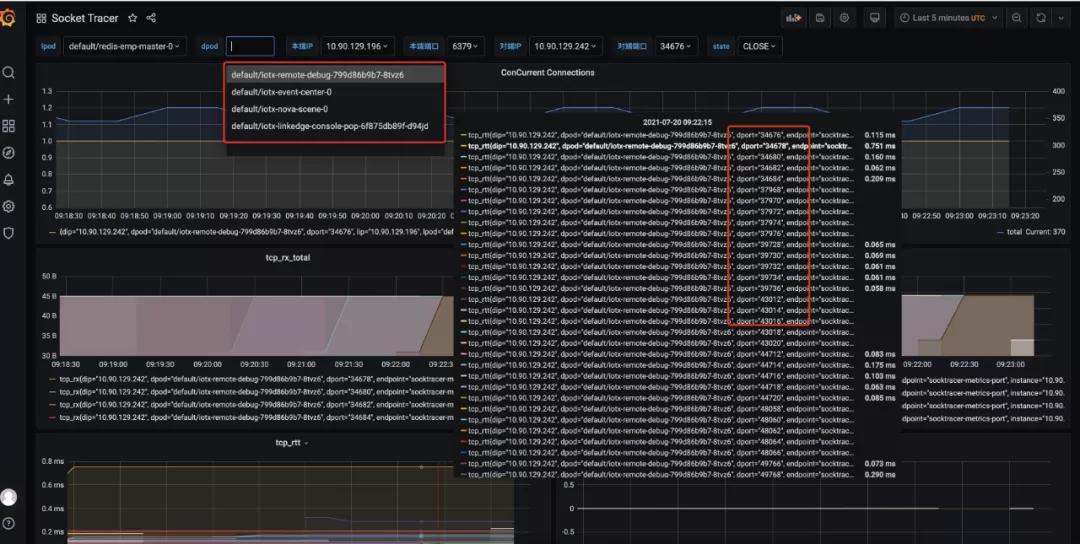
1.Grafana Dashboard
下图中,连接到 redis server 的所有TCP连接(来自不同的Client+Port)都会被监控,展示总并发连接数和连接的 rtt(延迟) 等信息:
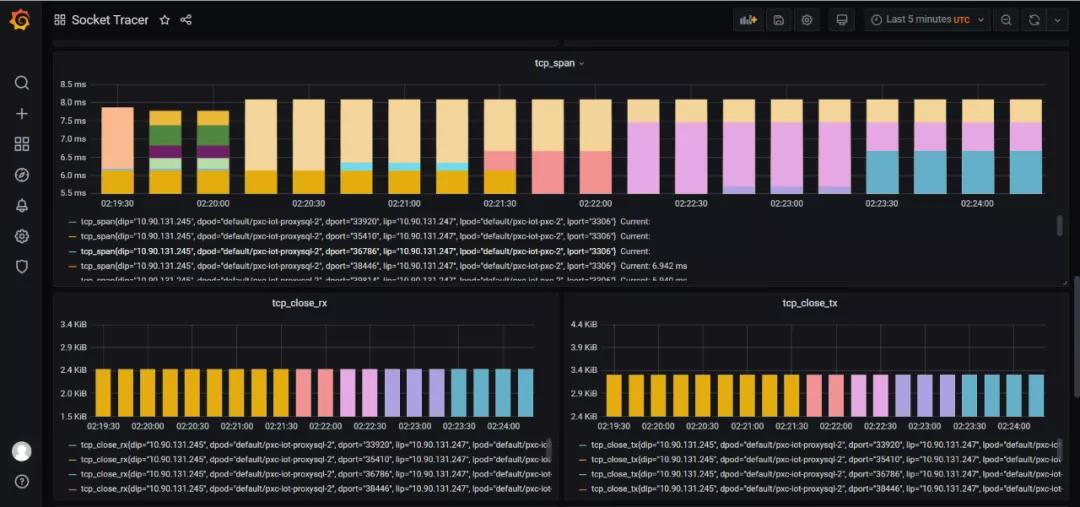
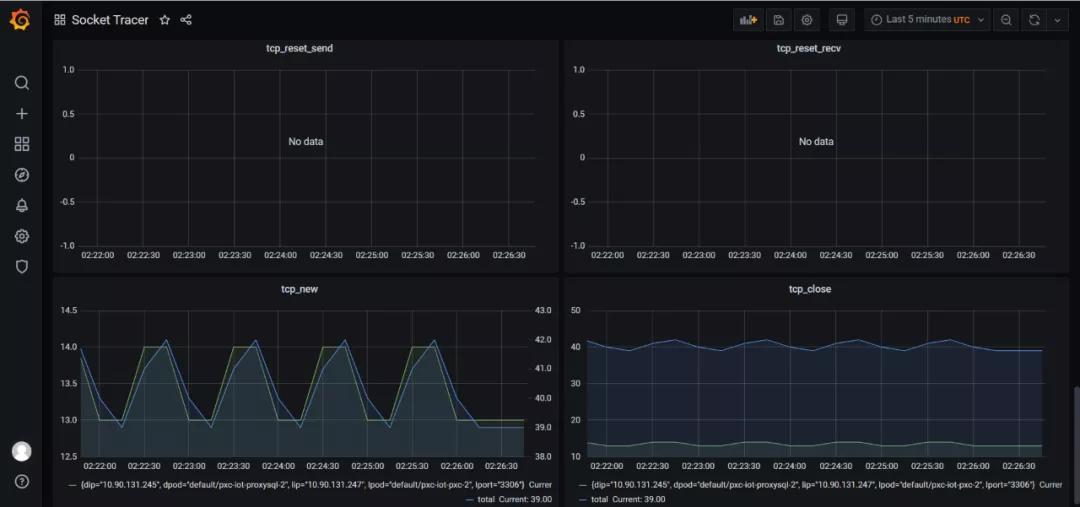
2.内核版本依赖(>=4.9)
Socket 信息采集依赖 tcp_diag 内核模块。
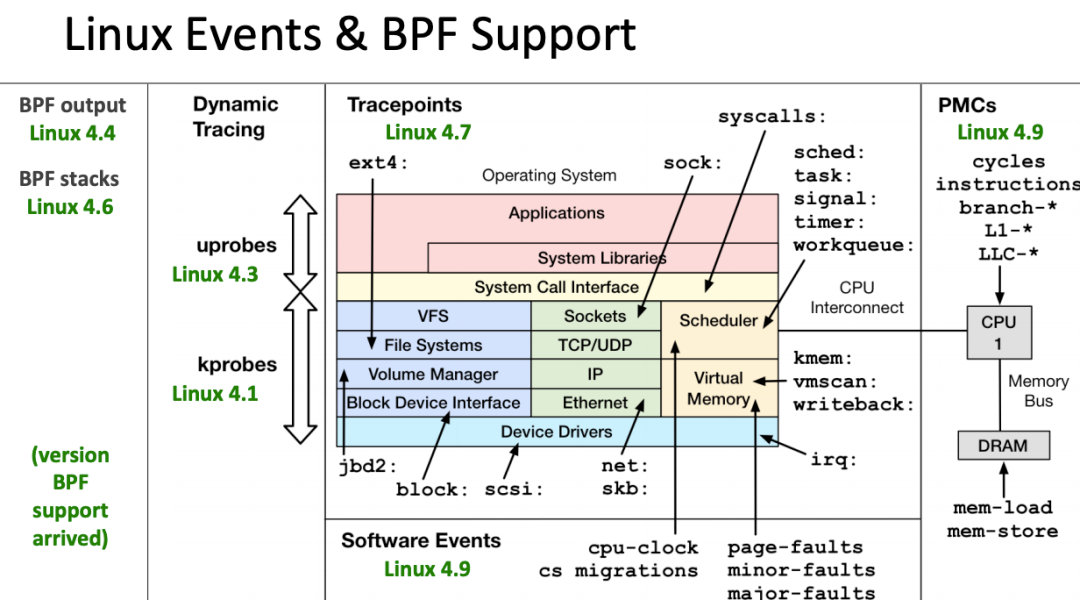
eBPF 还在快速发展期,内核中的功能也日趋增强,一般推荐基于Linux 4.4+ (4.9 以上会更好) 内核的来使用 eBPF。部分 Linux Event 和 BPF 版本支持见下图: