
最近,随着大数据和高性能硬件的发展,自回归语言模型(GPT)自编码语言模型(BERT)等待大规模预训练模型(PTM)取得了巨大的成功,不仅促进了自然语言处理(NLP)任务性能的提高也有效地提高了图像处理任务的性能。大规模预训练模型的突出优点是可以从大量未标记的数据中学习语言本身的知识,然后微调少量标记数据,使下游任务能够更好地学习语言本身的特征和特定任务的知识。这种预训练模型不仅可以充分利用广泛的网络资源,而且可以完美地解决人工标记数据更复杂的问题。因此,预训练模型几乎已经成为一个NLP任务标准[1]。
本文将分为上下两篇文章,解释预培训模型的诞生、代表性工作和未来的发展方向。上一篇主要介绍预培训的诞生和代表性工作,下一篇主要介绍预培训模型的未来发展方向。相关内容主要参考[1]。
1、背景介绍
近年来,包括卷积神经网络、循环神经网络和Transformer深度神经网络,包括模型,已广泛应用于各种应用。与传统的依赖人工特征的机器学习方法相比,深度神经网络可以通过网络层自动学习数据特征,摆脱了人工设计特征的局限性,大大提高了模型的性能。
虽然深度神经网络在促进各种任务方面取得了重大突破,但深度学习模型对数据的高高度依赖也带来了巨大的挑战。由于深度学习模型需要学习大量的参数,数据量少必然会导致模型过度拟合和泛化能力差。因此,早期阶段AI研究人员开始投身于为AI在任务手工构造高质量数据集的研究中。最著名的是李飞飞团队ImageNet图像处理数据集大大促进了图像处理领域的快速发展。然而,自然语言处理领域处理离散的文本数据,人工标记更为复杂。NLP该领域开始关注大量未标注的数据。
预训练模型的初步探索主要致力于浅层语义表达和上下文语义表达。最早关注的浅层语义表达是Word2Vec[2]等等,为每个单词学习一个固定的单词代码,然后在多个任务中使用相同的代码,以便表达方法必须带来不能表达单词多义的问题。为了解决上述挑战,NLP 研究人员开始探索具有上下文语义的单词嵌入表示[3][4][5]。到目前为止,具有代表性的单词嵌入表示BERT和GPT一系列预训练模型,包括GPT-3模型参数已达千亿级。预训练模型的发展如图1所示。
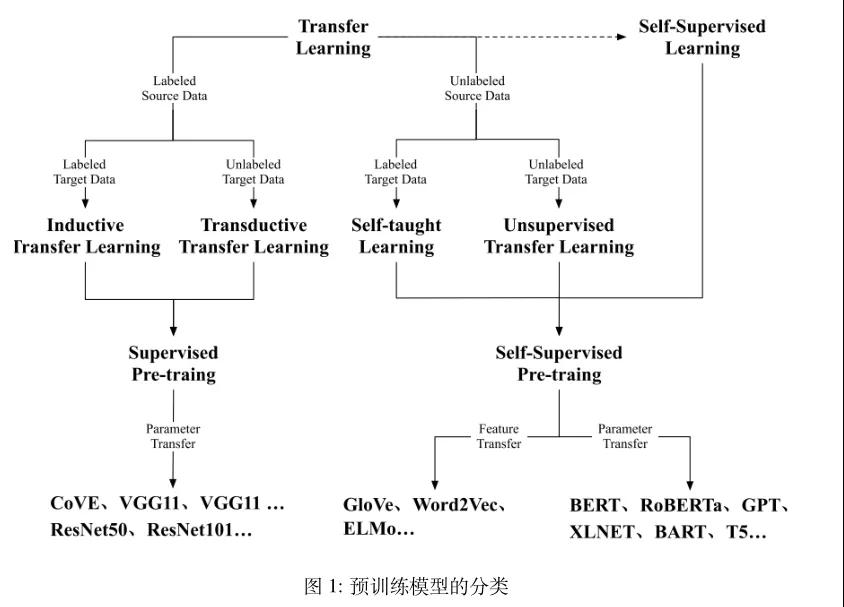
图1 预训模型分类
1.1 转移学习和监督培训
为了解决标记数据短缺导致的过拟合和泛化能力差的问题,提出了迁移学习。迁移学习受人类学习的启发,利用以前学到的知识来解决问题。它可以从多个任务中学习重要的知识,并将其应用于目标任务。因此,迁移学习可以很好地解决目标任务中标记数据短缺的问题。
预培训的早期工作主要致力于迁移学习[6],依靠以往的经验来解决新问题。在迁移学习中,原始任务和目标任务可能有不同的领域和任务设置,但所需的知识是一致的[7]。因此,选择一种灵活的方法将知识从原始任务转移到目标任务是非常重要的。提出预培训模型是为了建立原始任务和目标任务之间的桥梁。首先,预培训获得多个任务的一般知识,然后使用少量的目标任务标记数据进行微调,使微调模型能够很好地处理目标任务。
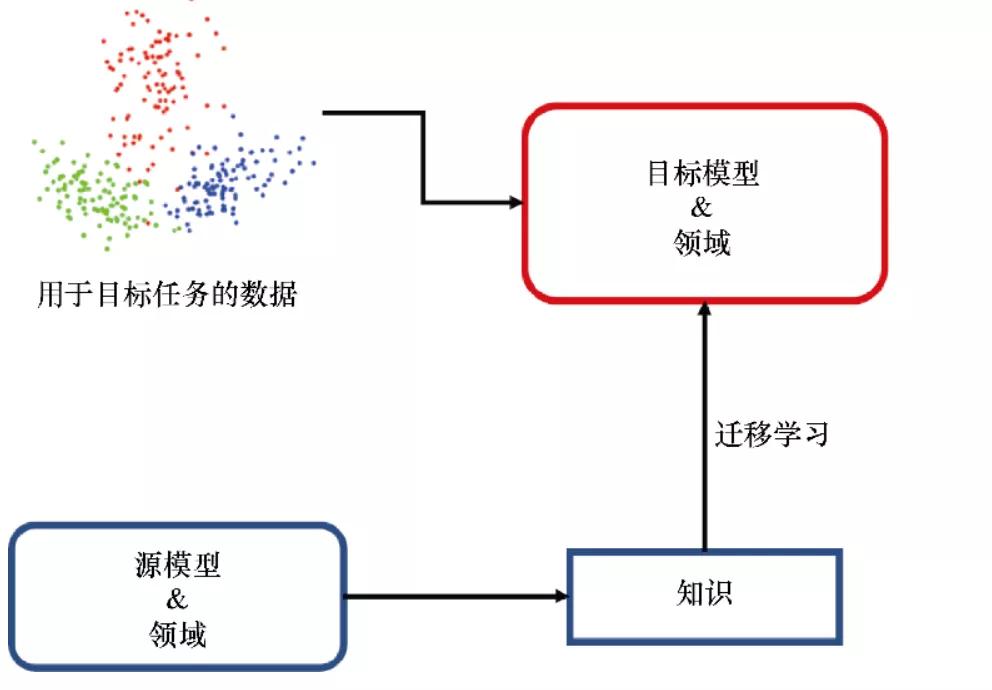
图2 迁移学习将现有知识重用到目标任务的原理图
一般来说,迁移学习有两种预训练方法:特征迁移和参数迁移。迁移学习在计算机视觉领域得到了广泛的应用ImageNet通过小数据集的微调,数据集上的预训练模型可以很好地应用于下游任务,这引发了预训练模型(Pre-trained Model,PTM)受此启发,NLP 社区也开始探索 NLP 任务预训练模型,最具代表性的工作是 CoVE[8]。图像处理领域最大的区别在于,NLP 没有人类标记的大量数据集,所以 NLP 社区开始充分利用大量未标记的数据,并在未标记的数据上使用自我监督方法,使预训练模型能够学习语言本身的特点。
1.2 自监督学习和自监督培训
迁移学习可分为四种子设置:归纳迁移学习、直接迁移学习、自学迁移学习和无监督迁移学习。归纳迁移学习和直接迁移学习是研究的核心,因为它们可以将监督学习中学到的知识转移到目标任务中。由于监督学习需要大量的标记数据,越来越多的研究人员开始关注大规模的无标记数据,并试图从无标记数据中提取关键信息。
自我监督学习是从无标记数据中提取知识的一种手段。它可以使用数据本身的隐藏信息作为监督,这与无监督非常相似。因为自然语言很难标记,而且有很多未标记的句子,所以NLP 领域的预训练模型主要致力于自我监督学习,大大促进了NLP发展领域。NLP任务早期的预训练模型是一个广为人知的单词嵌入代码。由于单词通常存在多义问题 [4],进一步提出了句子级单词嵌入代码模型,可以捕获单词的语义信息,该模型几乎成为目前的 NLP 任务最常见的模式之一是自回归语言模型(GPT)自编码语言模型(BERT)。受二者的启发,后期又提出了很多更高效的预训练模型,如 RoBERTa[9]、XLNET[10]、BART和T5[11]。
2、代表性工作
自我监督学习和预训练模型成功的关键Transformer代表性的工作是 GPT 和BERT系列模型。其他预训练模型都是这两个经典模型的变体。预训练模型的相关模型家族如图3所示。
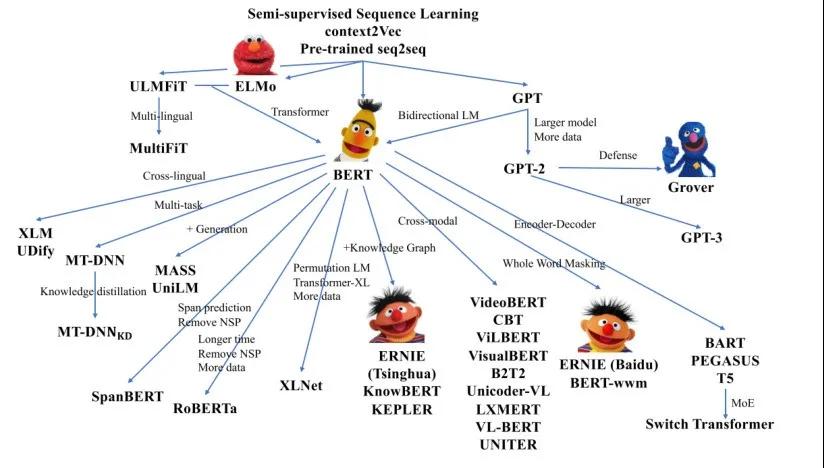
图3 近年来预训练模型家族
2.1 Transformer
Transformer是应用自注意机制的编码-解码器结构可以建模输入句子中不同单词之间的关系。self-attention平行计算机制,Transformer能够充分利用增强的计算设备来训练大规模模型。Transformer编码和解码阶段,self-attention该机制可以计算所有输入单词的表示,Transformer如图4所示。
在编码阶段,给定一个单词,Transformer注意力分数是通过比较单词和输入的其他单词来计算的。每个注意力分数显示了其他单词对单词表示的贡献,然后注意力分数被用作其他单词对单词的权重来计算给定单词的加权表示。给定单词的影响表示可以通过喂入所有单词表示的加权平均到全连接网络来获得。这个过程是整个句子信息回归的方法。在平行计算的帮助下,所有单词都可以同时生成句子表示。在解码阶段,注意力机制与编码阶段相似。唯一不同的是,它一次只能从左到右解码一个表示,解码过程的每一步都将考虑以前的解码结果。
由于优势突出,Transformer逐渐成为自然语言理解和生成的标准网络结构。此外,它还作为随后的衍生物PTM主干结构。下面介绍的GPT和BERT这两种模型完全打开了大规模的自我监督PTMs时代里程碑。总的来说,GPT擅长自然语言的生成,BERT更注重自然语言理解。
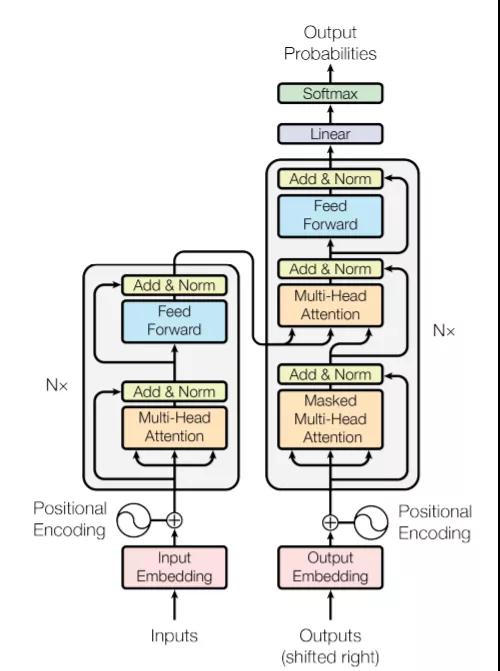
图4 Transformer的模型结构
2.2 GPT
PTMs主要包括预训练和微调两个阶段。GPT采用Transformer结构作为模型骨架,采用生成式预训练和识别微调。理论上,GPT是第一个组合Transformer在自然语言推理、问答任务、常识推理等方面,结构和自监督预训练目标的模型NLP在任务上取得了重大成功。
具体来说,给定一个无标签的大型语料库,GPT能够优化标准的自回归语言模型,即在给定的上下文中最大化单词的预测条件概率。GPT在预训练阶段,每个单词的条件概率由Transformer建模。GPT通过使用 GPT预训练参数是下游任务的起点。在微调阶段,输入序列通过 GPT,我们可以获得GPT Transformer 最后一层的表示。使用最后一层的表示和特定任务的标签,GPT使用简单的额外输出层来优化下游任务的标准目标,GPT模型的具体结构如图5所示。
由于GPT数亿参数,8个参数GPU训练了一个月,这是 NLP历史上第一个“大规模”的PTM,GPT后续一系列大规模成功PTM道路的兴起铺平了道路。
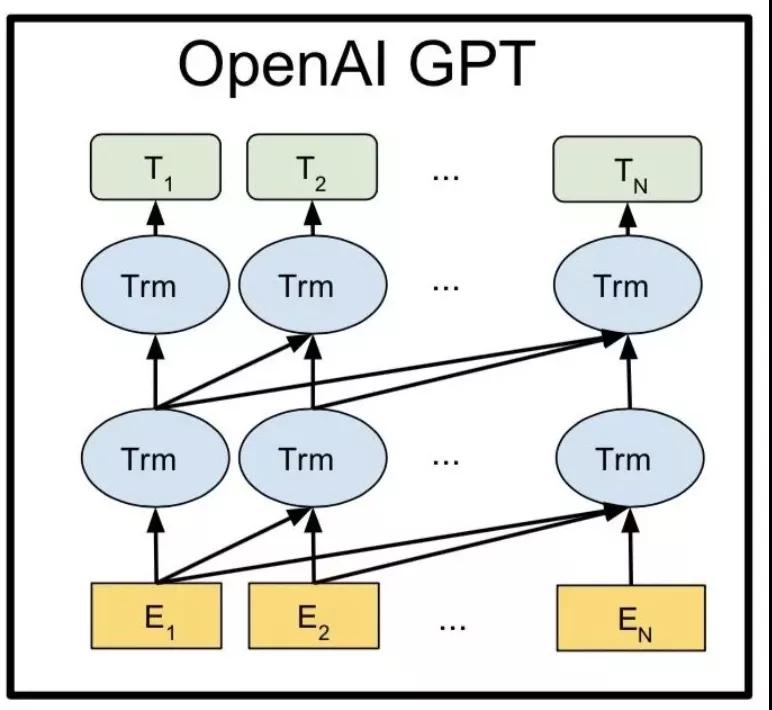
图5 GPT模型结构
2.3 BERT
BERT是另一个最具代表性的模型。GPT相比,BERT 采用双向深度Transformer作为主要结构,BERT如图6所示。BERT模型包括预训练和微调两个阶段。在预训练阶段,BERT受完形填空的启发,采用自编码语言建模提出了一种方法Mask语言模型(MLM),将目标词用[MASK]符号遮盖的目的是在预测遮盖词时考虑上下文的所有信息。GPT与单向自回归语言建模相比,MLM 可以学到深度和双向token的表示。
除了MLM除了任务,下一个预测也被使用(NSP)的目标来捕捉句子之间的话语关系,用于一些多个句子的下游任务。在预训练阶段,MLM和NSP共同优化BERT的参数。
预训练后,BERT可获得下游任务的稳定参数。修改输入和输出下游任务的数据,BERT 可针对任何 NLP 微调任务。BERT 这些应用程序可以通过输入单个句子或句子来有效地处理。对于输入,其模式是用特殊标记 [SEP] 连接的两个句子可以表示:(1)解释中的句子是对的;(2)含义中的假设-前提是正确的;(3)问答中的问题-段落对;(4) 单句用于文本分类或序列标记。BERT 将生成每个令牌token-level表示可用于处理序列标记或问答,特殊令牌 [CLS] 可输入额外层进行分类。
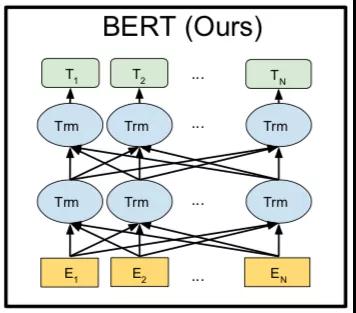
图6 BERT模型结构
2.4 GPT和BERT的子子孙孙
在GPT和BERT预训练模型之后,基于两者有了一些改进,比如RoBERTa和 ALBERT[12]。RoBERTa改进思路主要是消除NSP任务,增加训练步数和更多数据,并将[MASK]改为动态模式。实证结果表明。Roberta比BERT更好,并且RoBERTa 已指出 NSP 任务对于BERT训练相对无用。
ALBERT是BERT另一个重要的变体是减少模型的参数。首先,它将输入词嵌入矩阵分解为两个较小的矩阵;其次,它强迫所有 transformer 层之间的参数共享减少了参数;第三,它提出了句子顺序预测任务,而不是BERT的NSP任务。但是,由于牺牲了空间效率,ALBERT 微调和推理速度相对较慢。
除了 RoBERTa和ALBERT此外,近年来,研究人员还提出了各种预训练模型,以更好地从未标记过的数据中获取知识。一些工作改进了模型架构,并探索了新的预训练任务,如 XLNet[10]、UniLM[13]、MASS[14]、SpanBERT[15]和ELECTRA[16]。此外,研究人员还试图在模型中整合更多的知识,如多语言语料库、知识图谱和图像。
3、小 结
由于NLP该领域没有公开的大规模标记语料库,因此提出了预训练模型NLP模型能够充分地利用到海量无标注的数据,从而大大提升了NLP任务性能。特别是,GPT和BERT预训练模型的出现,让NLP该领域发展迅速。同时,优化完善的预训练模式如雨后春笋般涌现。下一篇将详细介绍相关探索工作。
参考文献
[1] Xu H,Zhengyan Z,Ning D,et al. Pre-Trained Models: Past,Present and Future[J]. arXiv preprint arXiv:2106.07139,2021.
[2] T. Mikolov,I. Sutskever,K. Chen,G. S. Corrado,and J. Dean, “Distributed representations of words and phrases and their compositionality,” in Advances in neural information processing systems,pp. 3111–3119,2013.
[3] O. Melamud,J. Goldberger,and I. Dagan,“context2vec: Learning generic context embedding with bidirectional lstm,” in Proceedings of the 20th SIGNLL conference on computational natural language learning,pp. 51–61,2016.
[4] M. E. Peters,M. Neumann,M. Iyyer,M. Gardner,C. Clark,K. Lee,and L. Zettlemoyer,“Deep contex-tualized word representations,” arXiv preprint arXiv:1802.05365,2018.
[5] J. Howard and S. Ruder,“Universal language model fine-tuning for text classification,” arXiv preprint arXiv:1801.06146,2018.
[6] S. Thrun and L. Pratt,“Learning to learn: Introduction and overview,” in Learning to learn,pp. 3–17,Springer,1998.
[7] S. J. Pan and Q. Yang,“A survey on transfer learning,” IEEE Transactions on knowledge and data engineering,vol. 22,no. 10,pp. 1345–1359,2009.
[8] B. McCann,J. Bradbury,C. Xiong,and R. Socher,“Learned in translation: Contextualized word vectors,” arXiv preprint arXiv:1708.00107,2017.
[9] Y. Liu,M. Ott,N. Goyal,J. Du,M. Joshi,D. Chen,O. Levy,M. Lewis,L. Zettlemoyer,and V. Stoyanov,“Roberta: A robustly optimized bert pretraining approach,” arXiv preprint arXiv:1907.11692,2019.
[10] Z. Yang,Z. Dai,Y. Yang,J. Carbonell,R. R. Salakhutdinov,and Q. V. Le,“Xlnet: Generalized autoregressive pretraining for language understanding,” Advances in neural information processing systems,vol. 32,2019.
[11] A. Roberts,C. Raffel,K. Lee,M. Matena,N. Shazeer,P. J. Liu,S. Narang,W. Li,and Y. Zhou,
“Exploring the limits of transfer learning with a unified text-to-text transformer,” 2019.
[12] Z. Lan,M. Chen,S. Goodman,K. Gimpel,P. Sharma,and R. Soricut, “Albert: A lite bert for self-supervised learning of language representations,” arXiv preprint arXiv:1909.11942,2019.
[13] L. Dong,N. Yang,W. Wang,F. Wei,X. Liu,Y. Wang,J. Gao,M. Zhou,and H.-W. Hon,“Uni-
fied language model pre-training for natural language understanding and generation,” arXiv preprint
arXiv:1905.03197,2019.
[14] K. Song,X. Tan,T. Qin,J. Lu,and T.-Y. Liu,“Mass: Masked sequence to sequence pre-training for language generation,” arXiv preprint arXiv:1905.02450, 2019.
[15] M. Joshi,D. Chen,Y. Liu,D. S. Weld,L. Zettlemoyer,and O. Levy, “Spanbert: Improving pre-training by representing and predicting spans,” Transactions of the Association for Computational Linguistics,vol. 8,pp. 64–77,2020.
[16] K. Clark,M.-T. Luong,Q. V. Le,and C. D. Manning,“Electra: Pre-training text encoders as discriminators rather than generators,” arXiv preprint arXiv:2003.10555,2020.